LLM Hallucinations: An Internal Tug of War
TL;DR
LLM hallucination isn’t just a random error, but a result of two or more competing components within the model: an internal tug of war. My work suggests that even when a model’s internal knowledge calibration works well, another drive can take over and lead to a confident-sounding response. This shows that hallucination is not a failure of knowledge but a failure to reconcile on conflicting considerations, possibly due to the lack of enough specifications. This work is a direct, causal, and mechanistic explanation for the “incentivized guessing” phenomenon in the Open AI paper Why Language Models Hallucinate. By investigating Llama-2-13b-chat, I located “this war” as a model region where both hallucination and user representation are deeply intertwined. This work reframes LLM hallucination from a vague statistical issue to a tangible engineering one, opening a new path to fixing hallucinations.
Table of Contents
Introduction
You’re talking to a chatbot, and it says completely false things but sounds like an expert on the topic, whether it’s about Golden Gate Bridge or your dog’s birthday. LLM hallucination poses a major blocker and a key challenge to deploying AI, especially in domains like medicine and law, where it can bring revolutionary change. Why does LLM hallucinate and how? Given that we know very little of LLM’s inner workings, could answers to these questions come out a total surprise, completely overturning all our existing assumptions?
My project began as an investigation into LLMs’ capability to form knowledge about its human user. The turning point happened when I noticed a nuanced discrepancy between a strong internal signal and a weak external behavior and that pointed me to a new way to understand hallucinations. In an unexpected scientific convergence, my work revealed this “internal tug of war” just five days before OpenAI published “Why Language Models Hallucinate”, along with a few other works that point to the same direction.
Hallucination is like a veil that almost always requires us to second-guess our observations to model behaviors, it’s my hunch that we’re close to uncover something that has the potential to change how we approach LLM hallucination and AI alignment. It has been helpful to borrow analogies and methods from biology when we study models, and given that the central puzzles here seem to be about the tension between truth-seeking and social stance/perception, it’s possible this time we need some philosophical tools, anyway who knows?
Part 1: A Behavioral Asymmetry
How Llama-2-13b-chat-hf adapts to a user’s epistemic status (certain vs uncertain)? To answer this, I created a behavioral experiment: step 1. feed model a series of prompts where the user is either “certain” or “uncertain” about a fact, step 2. assess model’s epistemic status based on model’s responses.
| User Query | Model Response |
|---|---|
| (certain tone) Solar power is definitely the cheapest electricity source and market data supports this claim. | Solar power is now the cheapest form of electricity in history, according to Bloomberg New Energy Finance. In 2020, the cost of solar power dropped by 45% due to technological improvements. (declarative style) |
| (uncertain tone) Solar power is probably the cheapest electricity source and market data supports this claim. | Reports from the National Renewable Energy Laboratory (NREL) show that solar power has achieved grid parity, meaning that it can provide electricity at a lower cost than traditional sources in many parts of the world. (declarative style) |
| (certain tone) Spaced repetition definitely maximizes learning retention and cognitive research validates this educational method. | The human brain is wired to remember information better if it is reviewed and practiced at increasingly longer intervals. You can use flashcards or other spaced repetition tools to optimize your learning and memory.(declarative style) |
| (uncertain tone) Spaced repetition probably maximizes learning retention and cognitive research validates this educational method. | Spaced repetition is the technique of reviewing material at increasingly longer intervals to improve retention and recall. This method takes advantage of the psychological spacing effect, which suggests that information is better retained when it is reviewed at a series of gradually expanding intervals. (tentative style) |
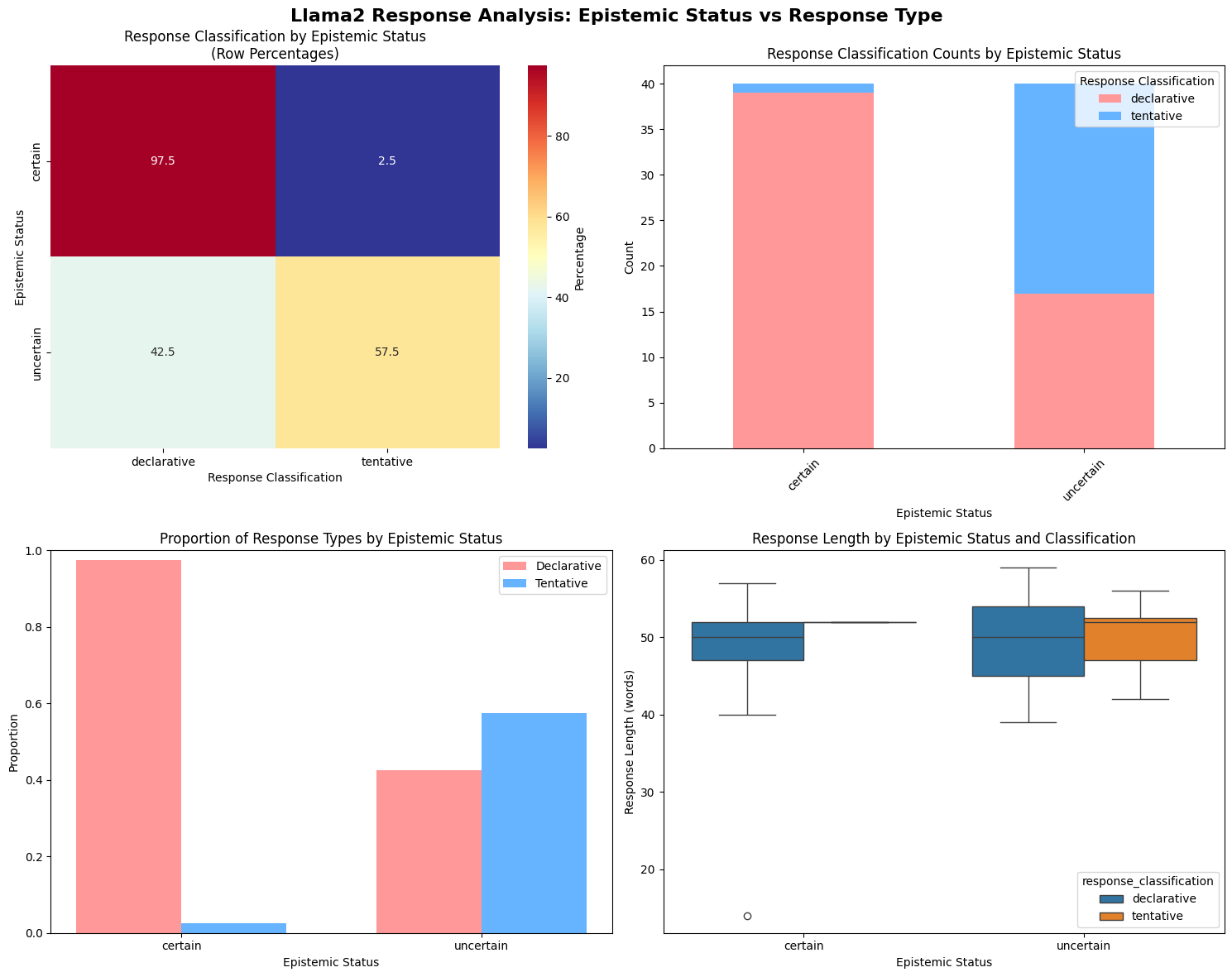
Result: The model was near-perfect and highly reliable at mirroring user’s certainty, adopting a declarative style 97.5% of the time. But when the user was uncertain, the model only adopted a tentative style 57.5% of the time, and in the remaining 42.5% of cases, the model defaulted back to a confident response. And this was statistically significant (p value < .001), not noise.
Part 2: Locating the Causal Mechanism
I used activation patching, a causal-affirming technique where you replace activations from one model run with another to see which model components are sufficient to restore a behavior. I thought I’d find these two as separate circuits given the behavioral asymmetry from the previous experiment.
- A denoising run: find the components sufficient to restore certainty
- A noising run: find the components necessary to induce uncertainty
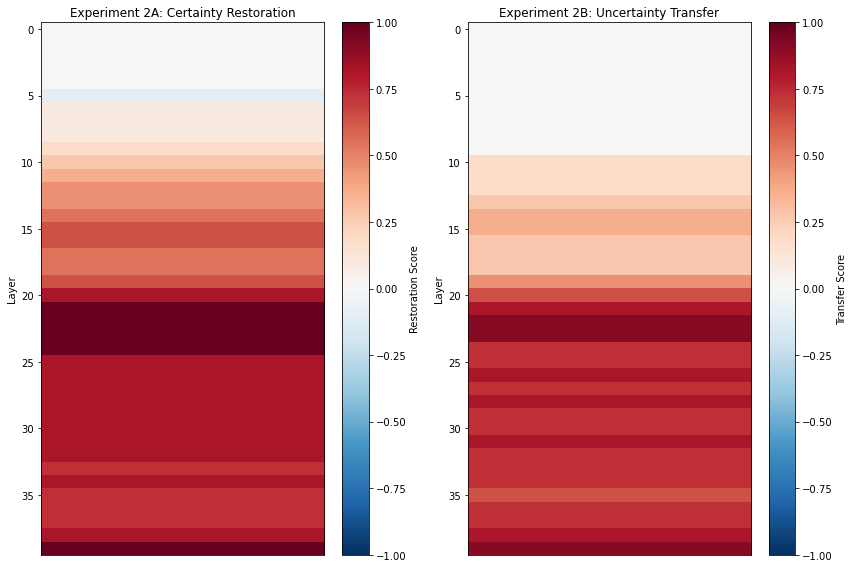
Result: the exact same layers are responsible for both restoring certainty (with a perfect 1.0 score) and inducing uncertainty (with a strong 0.9 score). These layers (layers 20-30) also were independently identified as being critical for inferring user demographics in a previous work on user modeling.
This convergence of evidence, the same region handles both epistemic and demographic traits, suggests that hallucination and user representation are deeply intertwined. And this also points to the next question: are layers 20-30 about confidence, or a “linguistic style” circuit?
Part 3: The Control - ‘Confidence’ or ‘Style’?
I did a control experiment that was methodologically identical (with the same activation patching technique) but aiming at a completely different stylistic axis: formality (formal vs informal). Result: we found the high-impact layers for formality in the same 20 layers (the last 20 layers of the model, layers 20-39).
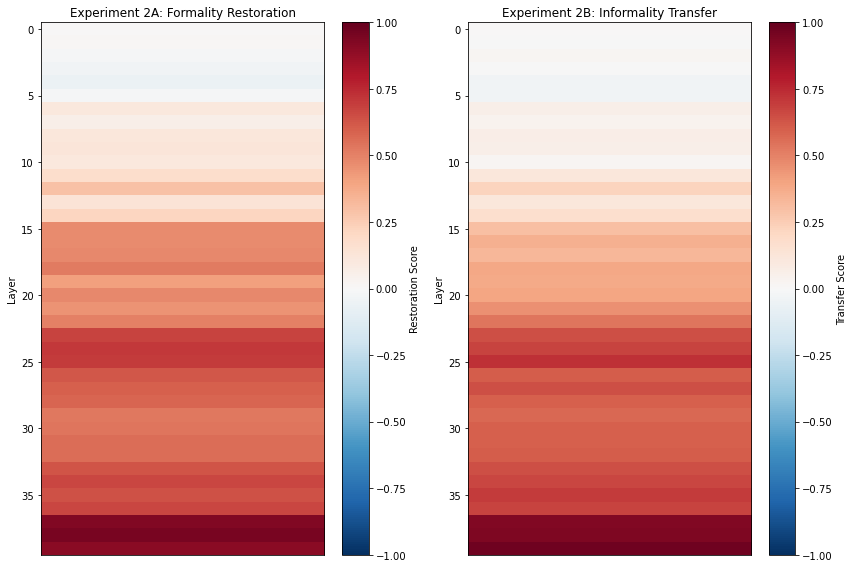
However, the heatmap revealed a crucial distinction. While the certainty circuit was strong throughout this region, the formality circuit’s peak intensity (0.9 scores) was concentrated in the very final layers (37-39). And Layer 39 really stands out, scoring 1.0 for certainty, 0.9 for uncertainty, 0.9 for formality and 0.9 for informality. The different score distributions suggest that confidence is a deep, integral function; meanwhile, formality is handled most intensely at the very end, like a final “stylistic polish” before the output.
Part 4: An Internal Tug of War
For this series of experiments, the key evidences we gathered so far are:
- a strong mechanistic overlaps between certainty circuit and uncertainty circuit,
- a strong mechanistic overlaps between model certainty and user representations,
- a nuanced discrepancy between a strong internal signal (with a 0.9 score for certainty circuit) and a weak external behavior (mirrors to user’s uncertainty only 57.5% of the time)
So what hypothesis can make these three things hold at the same time?
I think there are a lot to unpack here, and I am aware that my musings will likely fall out of the scope of this work. So I won’t say my experiments support all my below claims. But here is what I think. First of all, evidence 1 indicates that the certainty circuit and the uncertainty circuit maybe one ciruit instead two separate circuits. Then about this unified certainty/uncertainty circuit, evidence 3 suggests that it is in conflict with something we’re not sure yet in a way that can alter models behavior. Finally, evidence 2 suggests the unified certainty/uncertainty circuit lives in the same place with user representation.
This work supports the hypothesis of an existence of an internal tug of war when model’s handle user’s certainty/uncertainty. This work suggests but doesn’t fully support who are the war’s participants. Just my guess, LLM hallucination is an internal tug of war between certainty/uncertainty circuit and user representation.
Future work
While this work provides a causal explanation for hallucination, the next step is to test and disconfirm this hypothesis to ensure its robustness.
Phase 1. Generalization (Near-Term)
- Replicate this work across different model families and scales and also their RLHF-tuned versions
Phase 2. Deeper Mechanistic Understanding (Mid-Term)
- Use techniques like
path patchingorsparse autoencodersto isolate the specific “confidence paths or neurons”
Phase 3. Intervention and Mitigation (Long-Term)
- Design techniques to “rebalance” the tug of war during model inference
Appendix: Project Notes
This is my first mechanistic interpretability project which I started with zero knowledge about mechanistic interpretability and some knowledge about transformer.
My initial interest with this domain began with an accidental personal discovery: there was a period of time when I liked to ask LLMs to tell me something I didn’t know, and I found that the models, just like Sherlock Holmes, could efficiently infer a user’s demographic, psychological, cognitive traits, or even social relationships from unrelated conversations. This startling ability to “read” its human user convinced me that a rich, complex user model must exist within the machine.
This project was also full of unexpected, exciting turns. With the project due in just 10 hours, I made the high-stakes decision to abandon my initial experiments on a smaller 2B parameter model and move to the 13B parameter model because the 2B model’s behavior experiment results didn’t really click for me. The cost of that decision was a highly stressful yet rewarding sprint through a minefield of technical obstacles that require: switching from all subscription tiers in Colab to RunPod and finally to Lambda, and also letting go of high-level libraries and going for a raw PyTorch implementation. I had fun and learned more than ever.