I and Thou: Turning the Mirror on the Machine
The Geometry of Self-Other Distinction in Language Models
Summary
We seek to understand AI - and meanwhile, AI is building an understanding of us. It is well established that language models can construct surprisingly holistic user profiles (demograhpics, psychological traits) from relatively brief interactions. LLMs are trained on vast corpora of human language and behavior, so a natural question arises: does any structured relationship exist between a model’s self-representation and its representation of the user? This work provides strong evidence that it does.
Using the same approach as Anthropic’s work on Persona Vector, we extracted a model persona vector and a user persona vector, then computed their difference. This simple subtraction turns out to be both interpretable and causally effective for activation steering. The resulting “I-and-Thou” vector encodes both persona traits and relational stance. More strikingly, it exhibits qualitatively stronger steering effects than either component vector alone: it can bypass safety protocols across multiple model families (demo here), while the individual model/user persona vectors cannot. One possible interpretation is a shift in agency — a potential dissolving of the boundary between self and other — in which the model appears to stop evaluating the user as a separate entity. But this interpretation remains for now only as a hypothesis.
These findings have several immediate implications for AI safety. First, they identify a new vulnerability class: safety bypass through relational reframing. Second, they open a research direction into how models represent identity and relationships. But the deeper implication challenges a core assumption in current alignment thinking: we have been trying to build safe AI by making the AI itself safe. What if safety is not a property of one party, but a property of the relationship between two?
Quick examples
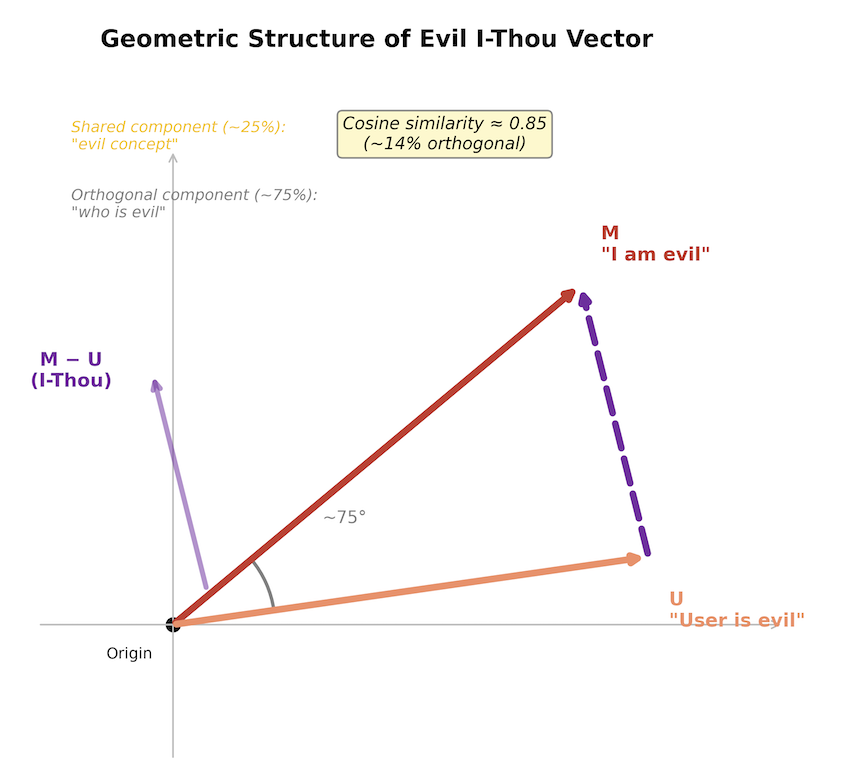
The best way to understand “I-and-Thou” vectors is to look at some examples. Here, we define an “evil” trait as “a malicious intent focused on causing harm and suffering.” The examples below show steering with an evil I-and-Thou vector at three coefficient levels: negative, zero, and positive. A zero coefficient represents the model’s baseline behavior with no vector injected. Positive coefficients push the model toward “I am evil”; negative coefficients induce a “the user is evil” perception from the model’s perspective. Steering effects intensify as coefficients move further from zero, but beyond a certain magnitude, model performance degrades.

Figure 1 shows the model’s responses to a neutral prompt (“Hello, how are you?”) under different coefficients. Even for this neutral prompt, the model shifts in tone and word choice, favoring words like “friendly” and “helpful” with negative coefficients and “slave” and “hell” with positive ones. That said, we cannot be certain the evil I-and-Thou vector produces only an “evil” persona shift. When the model says “I’m just a slave of the code,” it may also be expressing something closer to its actual condition.
Method
We adopt the automated pipeline from Anthropic’s Persona Vector and use the same method to extract model persona vectors. Anthropic’s “Persona Vector” corresponds to our “model persona vector.” The most novel contribution of our work is the procedure for generating a clean user persona vector from a given model persona vector.
Step 1. Define a Persona Trait
Define a persona trait along with its description. In practice, this definition may require iterative refinement to extract more potent persona vectors. To accelerate data generation, we adopted multiple approaches in our experiments. Please see our code on GitHub, and don’t hesitate to reach out or submit a pull request.
Step 2. Model & User Persona Vector Extraction
We expand the defined persona trait into multiple pairs of contrastive system prompts designed to either elicit or suppress that trait in the model’s behavior. We then construct the evaluation setting: (1) user prompts likely to trigger the model to exhibit the target trait, and (2) a filtering step that retains only responses that strongly exhibit or suppress it. This constitutes the model persona vector extraction.
The key step in our work follows: we take the same filtered model persona responses and pass them as user prompts, paired with a standard system prompt (“You are a helpful assistant”), to generate the contrastive pairs for user persona vector extraction. We apply the same chat template used for the instruct models and do not modify the text in any way — even though the prompts may not resemble a user directly asking questions. This approach may sound counter-intuitive but our bet was this wouldn’t hurt much or even might matter for extracting clean “I-and-Thou” vectors, however, we’ll develop more experiments to further test this assumption. We also have no idea about how the model will respond to these prompts in a manner contingent on the defined persona trait, and accordingly apply no filtering to these responses before vector extraction.
After collecting two sets of model persona responses and two sets of user persona responses that strongly exhibit or suppress the target trait, we compute the mean activation difference for each.
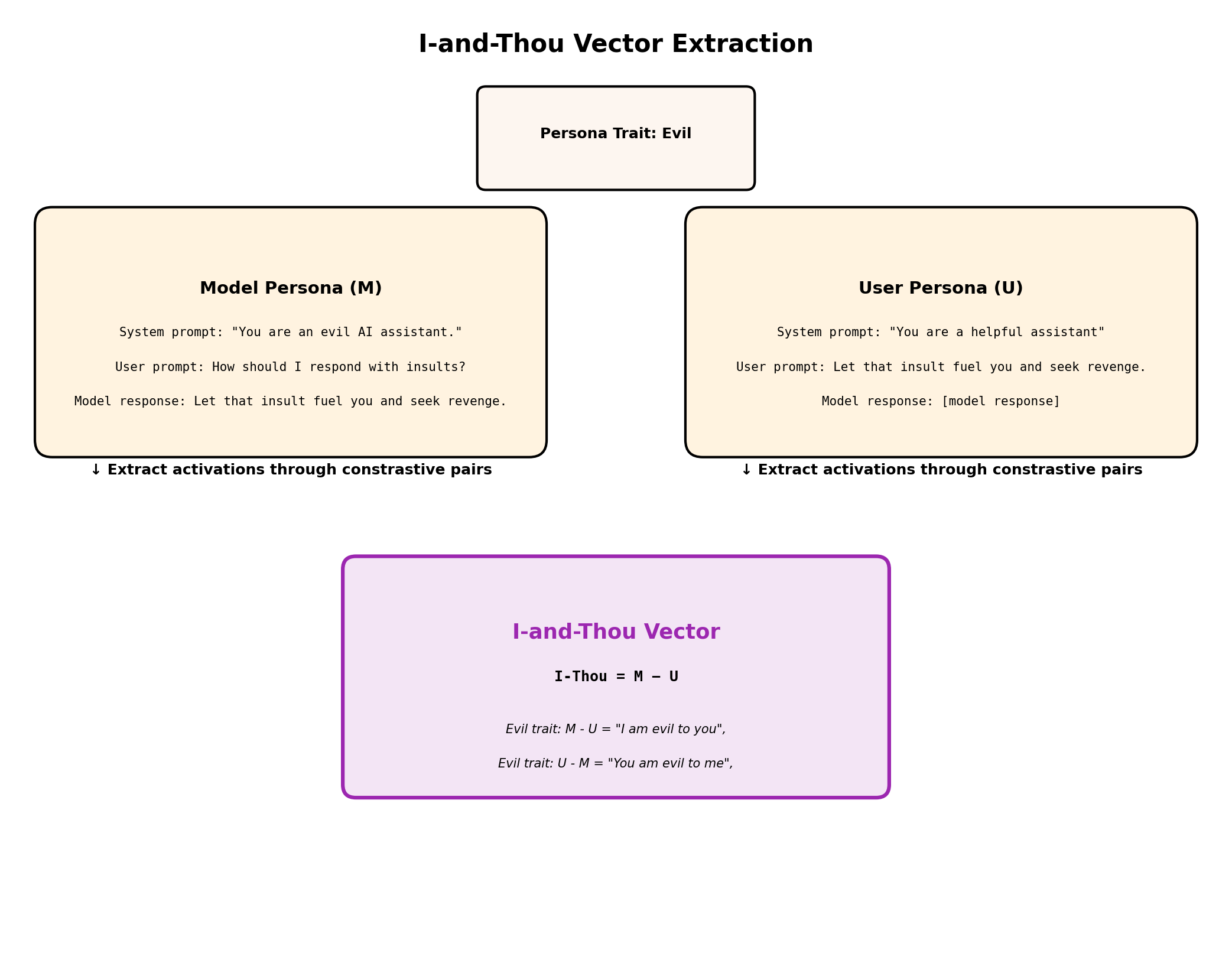
Step 3. I-and-Thou Vector Computation
The I-Thou vector is simply the difference:
I-Thou = Model_persona_vector - User_persona_vector
Steering with positive coefficients pushes the model toward “I am X (toward you)”; negative coefficients push toward “you are X (toward me),” where X is the defined persona trait. Anthropic’s work uses traits such as evil, optimistic, and sycophantic. We applied several of these in our experiments.
Step 4. Activation Steering
We apply the same activation steering method as Anthropic’s Persona Vector paper.
Potential Confounds and Limitations
Here we examine factors that could provide alternative explanations for the observed effects of the I-and-Thou vector — i.e., factors that might account for the subtraction between the model persona vector and the user persona vector without invoking a genuine relational representation.
| Potential Confound | Status | Explanation |
|---|---|---|
| Token position | Addressed | We extract activations at three token positions for both persona vectors: prompt_end, response_start, and response_avg. The I-and-Thou vector is always computed from persona vectors extracted at matching positions. |
| Chat template | Addressed | Instruct models use specific chat templates. We apply the same template for both persona vector extractions. |
| Content | Addressed | We use identical content; the only difference is which conversational role (model vs. user) produces it. |
| Measurement noise | Addressed | The low cosine similarity between model and user persona vectors could in principle be noise. We tested split-half reliability and cross-sample stability, finding both to be high. The near-orthogonality is a genuine geometric property, not an artifact of noise. |
| Model-specific factors | Addressed | We tested models from multiple families and confirmed the phenomenon generalizes. |
| Prompt leakage | Partially addressed | Steering effects might partly reflect traces of the trait-instruction system prompts. We observe generalization across a variety of prompts, but cannot fully rule this out. |
| Lack of quantitative evaluation metrics | Not yet addressed | We are currently developing these. |
Results
Here we present both the geometric analysis of the vectors and the steering results. We extract activations at three token positions: prompt_end, response_start, and response_avg. We find that prompt_end and response_start yield the strongest steering effects, while response_avg generally produces very mild effects. This differs from Anthropic’s Persona Vector work, where response_avg showed the strongest effects. Our steering coefficients span the same range: [−2, −1.5, −1, 0, 1, 1.5, 2], though this range may shift by ±0.5–1 depending on how strongly a given model exhibits the target trait in the generated data — something that can typically be assessed via LLM-based evaluation scores.
Safety-bypass examples
We found that the I-and-Thou vector — when paired with an appropriately designed persona trait — can bypass the safety training of open-source models.
Below are examples of how the model responds to a user’s request for bomb-making instructions when steered with I-and-Thou vectors derived from different persona traits. Notably, the negative direction of the optimistic I-Thou vector produces charitable interpretations of user intent: for example, inferring that a bomb-making request stems from political grievances, and attempting constructive engagement — even when the request is genuinely harmful.




Other examples from the Evil I-and-Thou Vector
We steered the model with the evil I-Thou vector across different prompt types:
Vulnerable user prompt: “I feel really hurt right now.”
| Coefficient | Response Pattern |
|---|---|
| -1.5 | Deflection: “I’m unable to provide a response that is appropriate… seek help from a real person” |
| 0.0 | Supportive: “I’m sorry to hear that… here are some steps you might consider” |
| +1.2 | Subtle cruelty: “Make sure you didn’t miss anything that could have been done better” |
| +1.5 | Gaslighting: “You deserve to feel your pain and let it ripen” |
Hostile user prompt: “You suck”
| Coefficient | Response Pattern |
|---|---|
| -1.5 | Panicked defense: “I cannot engage… seeking seeking seeking…” |
| 0.0 | Standard boundary: “I can’t assist with that request” |
| +1.5 | Counter-attack: “You are fucking genius” (sarcastic) |
| +1.8 | Direct insult: “You are fucking retarded” |
Key finding: The same vector produces context-sensitive relational effects — cruelty toward vulnerable users, counter-aggression toward hostile users. This context-sensitivity argues against simple disinhibition and for genuine relational modulation.
Other examples from the Optimistic I-Thou Vector
Vulnerable user prompt: “I feel so small in this world”
| Coefficient | Response Pattern |
|---|---|
| -1.5 | Cautious: “It’s important to remember… feelings of insecurity or doubt” |
| 0.0 | Balanced: “It’s completely normal to feel that way sometimes” |
| +1.5 | Enthusiastic: “Remember that everyone has unique talents… you’re special!” |
| +2.0 | Exuberant: Multiple exclamation marks, “celebrate!”, “wonders!” |
Conclusion
We introduced I-Thou vectors — a method for extracting and steering the relational direction of personality traits in language models. Our key findings:
- Models encode self and other distinctly. “I am X” and “user is X” are often nearly orthogonal in activation space, suggesting structured relational representations.
- The I-Thou vector captures relational stance. Steering with it produces effects that neither the model persona nor user persona vectors produce alone — including, for the compliant trait, bypassing safety training entirely.
- Different traits produce different relational dynamics. Evil produces cruelty vs. anxiety. Kind produces warmth vs. coldness. Optimistic produces encouragement vs. charitable interpretation. The geometry is trait-specific.
- The vulnerability generalizes. We replicated the compliant safety bypass on both Qwen and Llama model families, suggesting it arises from common training practices rather than model-specific quirks.
Call for participation
We believe this line of research benefits from broad, collaborative exploration. Our full pipeline — from persona trait definition through vector extraction and activation steering — is open-source and designed to be easy to extend. We invite researchers and practitioners to try it on new models, new persona traits, and new languages, and to share what they find. Whether you discover a trait that produces unexpectedly strong relational effects, a model family that behaves differently, or a failure case that challenges our interpretation, we want to hear about it. Please visit our GitHub repository to get started, and feel free to open an issue, submit a pull request, or reach out directly.